みなさま、こんにちは
Tachanです。
今回はOCIのデータ・サイエンスサービスを使い、アヤメの品種判別を機械学習させる記事を書いていこうと思います。
Part2はサンプルデータからアヤメの品種判別、分類を行っていきます。
Conda環境の設定
機械学習ライブラリをインストールしたConda環境を作成します。
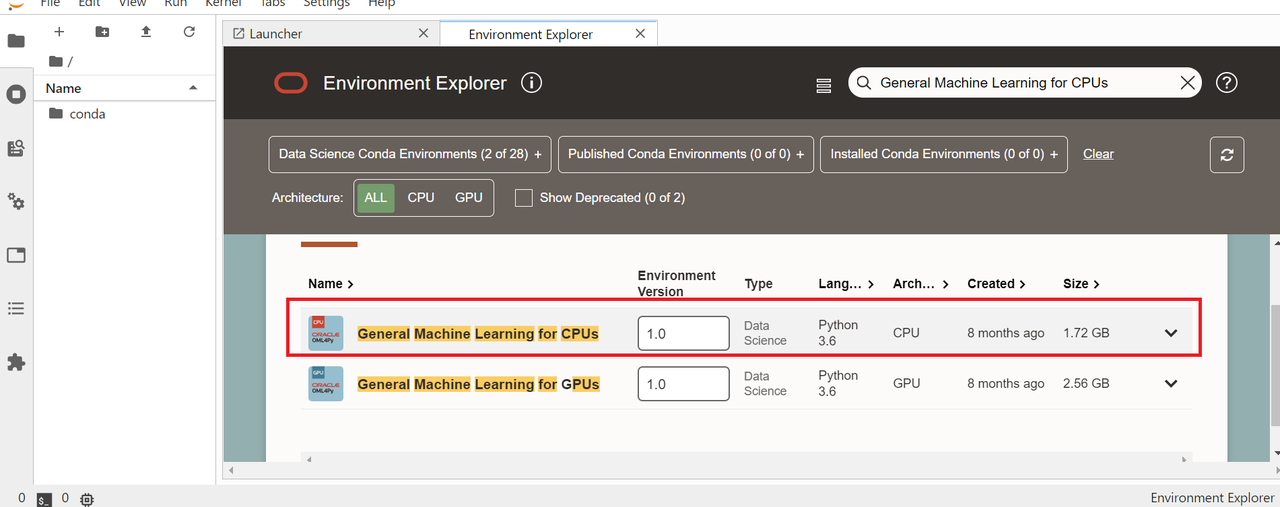
ノートブックを開き、NotebookカテゴリのEnvironment Explorerを選択します。
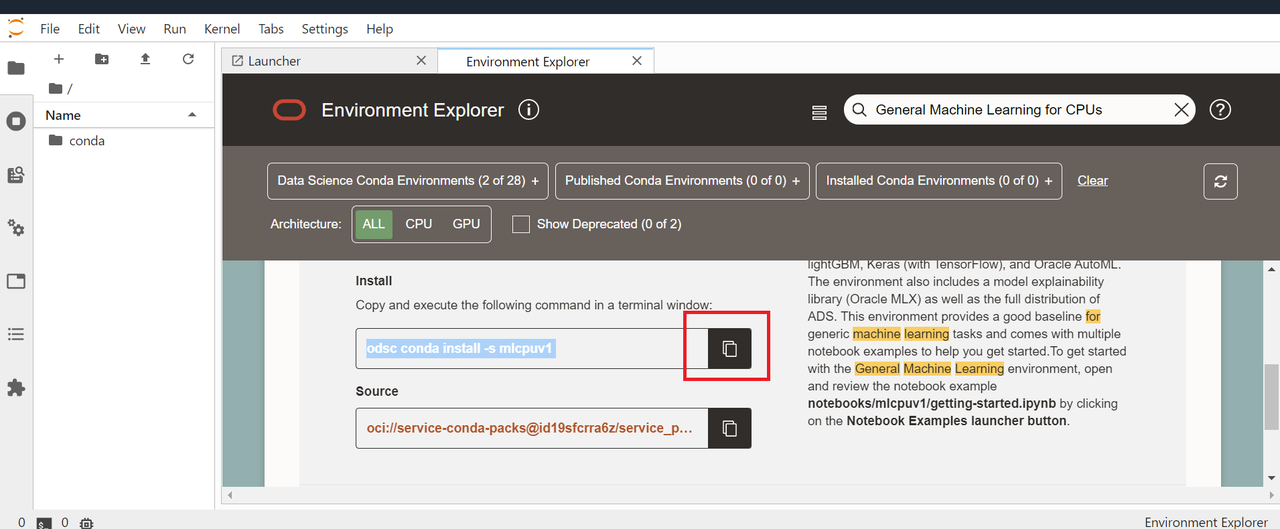
「General Machine Learning for CPUs」を検索し、インストール欄に書かれてあるコマンドをコピーします。
画面左上の「+」ボタンからランチャーを開き、OtherにあるTerminalを選択します。
Terminalで、先ほどコピーしたコマンドを張り付け、実行します。

インストールが終わったらscikit-learnもインストールします。
アヤメのデータの中身
scikit-learnをインストールしたら、アヤメのサンプルデータを読み込み、中身を確認します。
from sklearn import datasets
iris=datasets.load_digits()
dir(iris)
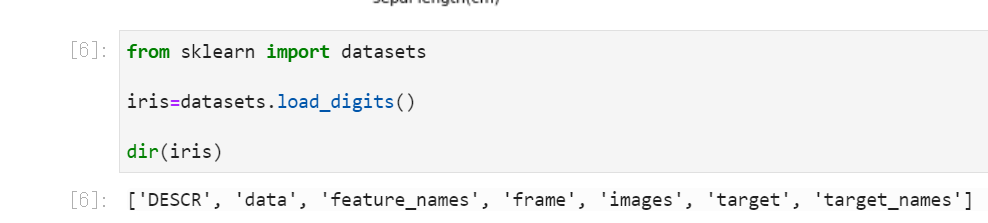
実行すると、データセットには5種類のデータが入っていることが分かります。
['DESCR', 'data', 'feature_names', 'frame', 'images', 'target', 'target_names']
それぞれに何が入っているのでしょうか。
DESCRでは、データセットの説明が記載されています。
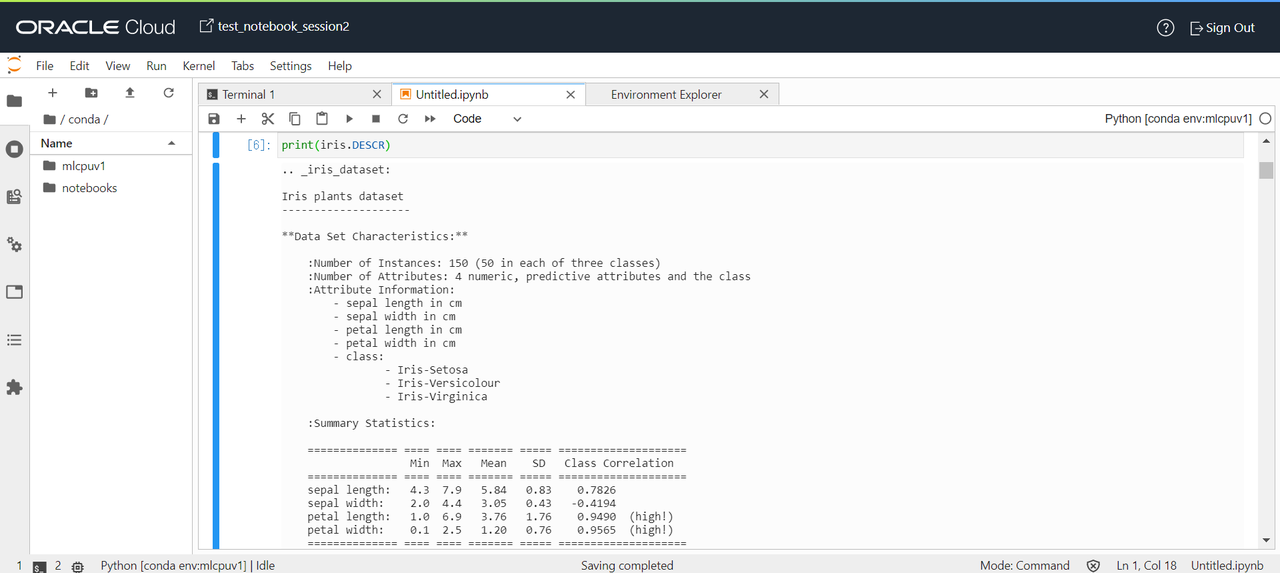
説明では以下の記述がされています。
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes) #3種類のデータが50個ずつ計150個入っている
:Number of Attributes: 4 numeric, predictive attributes and the class #データには4つの数値がある
:Attribute Information: #4つの数値の詳細
- sepal length in cm #アヤメのがく片の長さ
- sepal width in cm #アヤメのがく片の幅
- petal length in cm #花弁の長さ
- petal width in cm #花弁の幅
- class: #3種類のデータの名前(アヤメの名前)
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
(以下略)
Dataにはアヤメのがく片と花弁のデータが入っています。
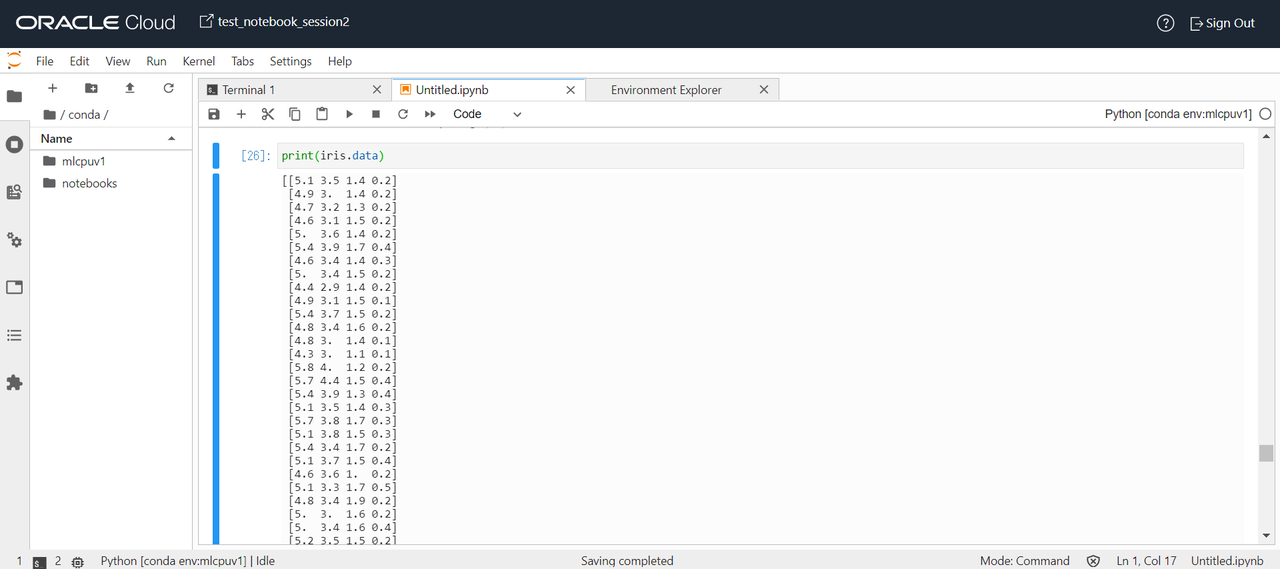
feature_namesでは上記の4つがどの項目の数値なのかを表しています。

targetでは0、1、2の数値が入っています。
target_namesでは上記のtargetの0、1、2の名前情報が入っています。
つまり、0がsetosa、1がversicolor、2がvirginicaに該当します。
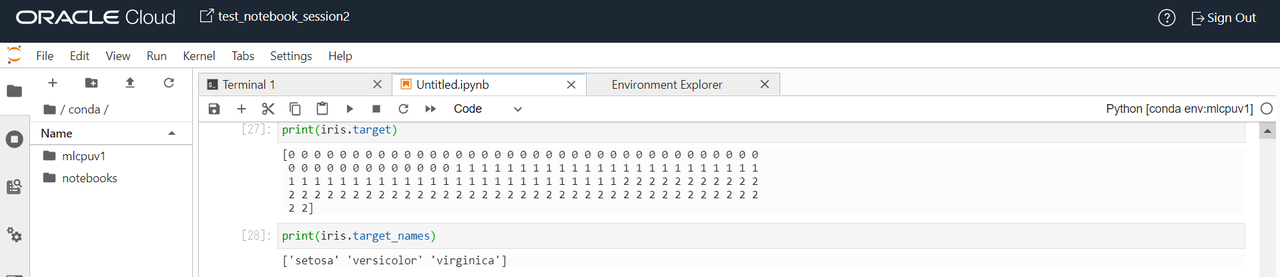
データセットの中身は以上になります。
学習モデルの作成と評価
今回はデータを訓練用とテスト用に分け、ロジスティック回帰でモデルを生成・評価します。
ロジスティック回帰とは、説明変数に基づき、目的変数が0もしくは1・YES/NOのように
2つの値で分類できる場合に使われる学習法です。
説明変数とは目的変数の予測のために使われる変数であり、
目的変数とは予測したい変数を指します。
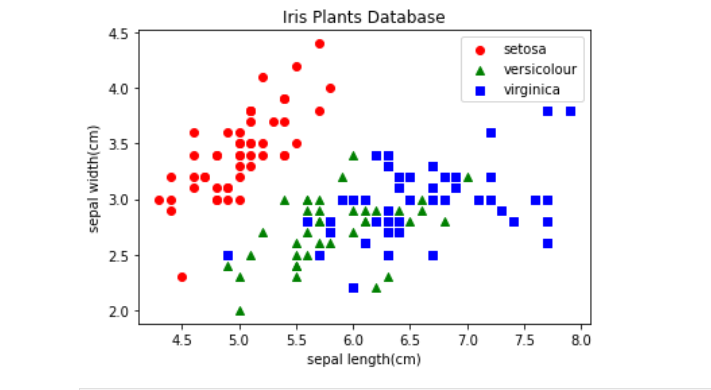
今回データに含まれている、がくの長さと幅、花弁の長さと幅をそれぞれ散布図にすると以下のようになり、この4つの値を使って種類の判別ができそうです。
<がくの長さと幅の散布図>
from sklearn import datasets
import matplotlib.pyplot
iris=datasets.load_iris()
a = iris.data
b = iris.target
matplotlib.pyplot.scatter(a[:50, 0], a[:50, 1], color='r', marker='o', label='setosa') #iris.dataの0番目から49番目のデータ範囲で、各データの0番目と1番目を使用
matplotlib.pyplot.scatter(a[50:100, 0], a[50:100, 1], color='g', marker='^', label='versicolour') #50番目から99番目のデータ範囲
matplotlib.pyplot.scatter(a[100:, 0], a[100:, 1], color='b', marker=',', label='virginica') #100番目から最後のデータ範囲
matplotlib.pyplot.title("Iris Plants Database")
matplotlib.pyplot.xlabel('sepal length(cm)')
matplotlib.pyplot.ylabel('sepal width(cm)')
matplotlib.pyplot.legend()
matplotlib.pyplot.show()
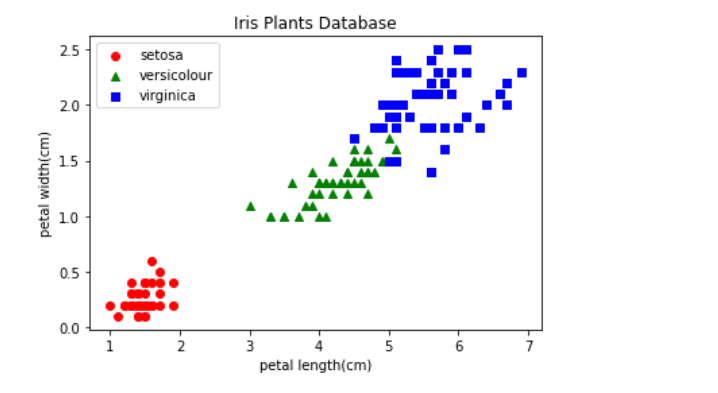
<花弁の長さと幅の散布図>
matplotlib.pyplot.scatter(a[:50, 2], a[:50, 3], color='r', marker='o', label='setosa')
matplotlib.pyplot.scatter(a[50:100, 2], a[50:100, 3], color='g', marker='^', label='versicolour')
matplotlib.pyplot.scatter(a[100:, 2], a[100:, 3], color='b', marker=',', label='virginica')
matplotlib.pyplot.title("Iris Plants Database")
matplotlib.pyplot.xlabel('petal length(cm)')
matplotlib.pyplot.ylabel('petal width(cm)')
matplotlib.pyplot.legend()
matplotlib.pyplot.show()
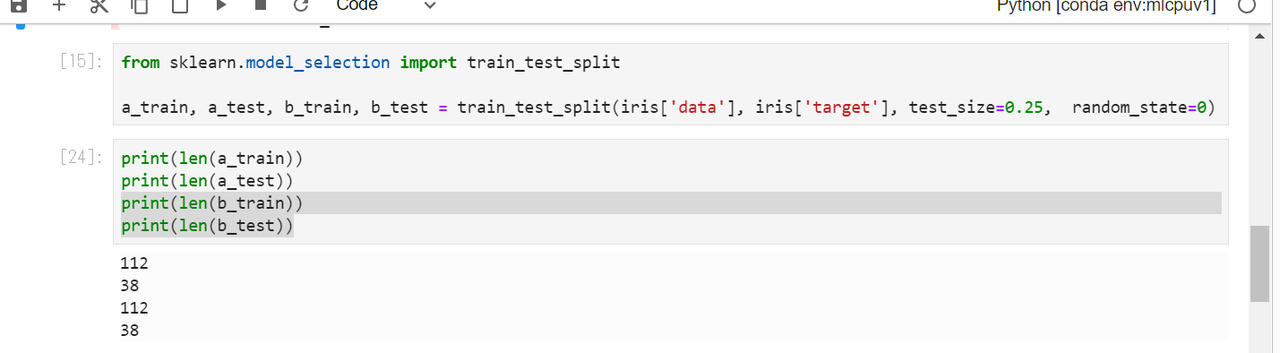
では、データを分けて、学習させていきます。
今回は、全体の75%を訓練データ、25%をテストデータに分割します。
from sklearn.model_selection import train_test_split
a_train, a_test, b_train, b_test = train_test_split(iris['data'], iris['target'], test_size=0.25, random_state=0)
printで出力してみると、問題なく分けられています。
次にロジスティック回帰で訓練データを学習させ、テストデータを用いてモデルを評価します。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression().fit(a_train, b_train) #訓練データ学習
score = logreg.score(a_test, b_test) #テストデータで評価
print('Test set score: {}'.format(score))

実行すると、結果は出たものの、「STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.」という
Warningが表示されました。
学習させた際に、最大反復回数に到達せずモデルが収束しなかったようです。
なので、max_iterで学習の反復の最大回数を200に設定してみました。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(max_iter=200).fit(a_train, b_train)
score = logreg.score(a_test, b_test)
print('Test set score: {}'.format(score))
すると警告は出ず、モデルの評価だけ表示されました。
品種判別させる学習モデルができました!

さいごに
以上でアヤメの品種判別分類を学習させることができました。
次はADSの特徴を生かしたモデルの構築・評価ができるような記事を書いていきたいと思います。
最後までお読みいただきありがとうございました。





![[日本語化]クラウド SIEM ダッシュボードと KPI を毎日のスタンドアップで使用して SOC の効率を向上させる方法](http://www.sumologic.com/wp-content/uploads/CloudSIEMdashboards_Blog_header_700x200-1-1.png)
