
みなさまお久しぶりです。Tachanです。
前回はラズパイでデジタルサイネージを開発した記事を書きました!
今回はその追加機能について書いていきたいと思います٩( 'ω' )و
追加機能の概要
今回追加した機能は
- 出勤状況確認アプリの表示
- 保守対応ダッシュボードの表示
になります。
それぞれ説明しますと、
出勤状況確認アプリは昨年Lさんが開発したもので、部員の出勤状況をリアルタイムで確認することができます。
保守対応ダッシュボードは、お問い合わせいただいたお客様からのフィードバックを表示しています。
今回はどちらもWebでアクセスするもののため、Seleniumを使ってみることにしました。
システム構成
今回は、PDFを表示する前にヘッドレスブラウザでスクリーンショットを撮る処理を追加しました。
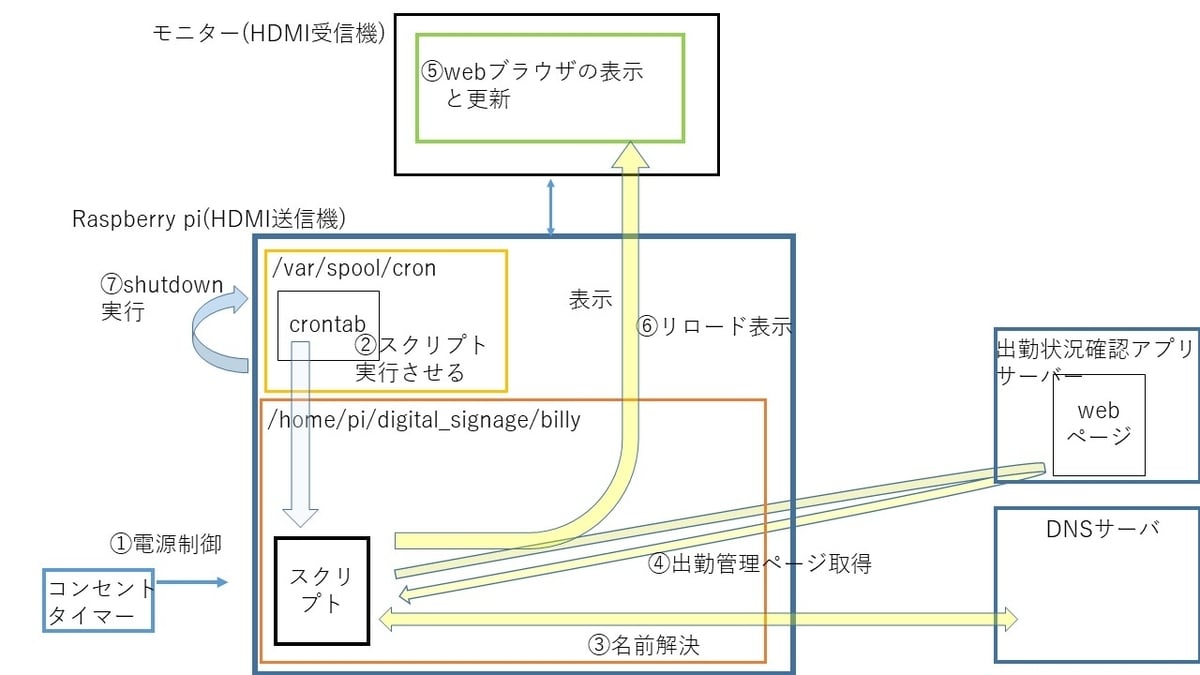
selenium処理の流れは
①指定URLにアクセス
②スクリーンショットを取得
③アルファチャンネルを取り除く作業
④③で作成した画像からPDFを作成
になります。
使ったモジュール
今回使ったモジュールは以下の3つです。
①selenium
Webアプリケーションをテストするためのソフトウェアです。
これを使ってブラウザ処理をヘッドレスで行うことができます。
②img2pdf
画像を加工できるモジュールです。
取得したスクリーンショットをPDFに変換する際に、アルファチャンネル(画像処理で、透過度の情報(アルファ値)を格納するデータ)を取り除かないといけなかったため、
こちらのモジュールを使って削除する処理を書きました。
③shutil
ファイルコピー、ディレクトリ階層のコピーや削除、ファイルやディレクトリの移動を行うことができるモジュールです。
スクリーンショットの画像や、加工した画像が溜まっていくので、それらのファイルを移動させるために使いました。
コード
実際のコードは以下です。
拡張機能は別ファイルで書き、それをメインのファイルで呼び出すことにしました。
- #!/usr/bin/python
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options
- from selenium.webdriver.common.action_chains import ActionChains
- import time
- import os
- import img2pdf
- from subprocess import check_output
- import subprocess
- import datetime
- import sys
- import shutil
- import glob
- class support_dashboard(object):
- def __init__(self):
- self.now = datetime.datetime.now()
- self.Before_filename_1 = 'pic1.jpg'
- self.Before_filename_2 = 'pic2.jpg'
- self.After_filename_1 = 'z1' + str(self.now.strftime('%Y%m%d_%H%M')) + '.jpg'
- self.After_filename_2 = 'z2' + str(self.now.strftime('%Y%m%d_%H%M')) + '.jpg'
- self.pdfFileName_1 = 'z1' + str(self.now.strftime('%Y%m%d_%H%M')) + '.pdf'
- self.pdfFileName_2 = 'z2' + str(self.now.strftime('%Y%m%d_%H%M')) + '.pdf'
- self.ext = '.jpg'
- self.path_1 = r'PDFを作成するディレクトリ' + str(self.After_filename_1)
- self.path_2 = r'PDFを作成するディレクトリ' + str(self.After_filename_2)
- self.options = Options()
- self.options.add_argument('--headless')
- self.browser = webdriver.Chrome(executable_path='/usr/bin/chromedriver', chrome_options=self.options)
- self.url = '保守対応ダッシュボードのURL'
- self.userid = 'ユーザーID'
- self.userpw = 'パスワード'
- def get_screenshot(self):
- self.browser.get(self.url)
- self.browser.set_window_size(1280,720)
- self.browser.execute_script("document.body.style.zoom='90%'")
- print(self.browser.current_url)
- time.sleep(10)
- self.browser.switch_to_frame(self.browser.find_element_by_tag_name('iframe'))
- time.sleep(10)
- login_id = self.browser.find_element_by_name('user[email]')
- login_pw = self.browser.find_element_by_name('user[password]')
- login_id.send_keys(self.userid)
- login_pw.send_keys(self.userpw)
- login_btn = self.browser.find_element_by_name('commit')
- login_btn.click()
- time.sleep(20)
- try:
- move_DashBoard = self.browser.find_element_by_class_name('クラス名')
- move_DashBoard.click()
- time.sleep(30)
- except:
- pass
- display_DashBoard = self.browser.find_element_by_xpath('パス')
- display_DashBoard.click()
- time.sleep(20)
- sfile = self.browser.get_screenshot_as_file('保存するパス' + self.Before_filename_1)
- print('get_screenshot1')
- print(sfile)
- time.sleep(5)
- target = self.browser.find_element_by_css_selector('cssの要素')
- time.sleep(3)
- self.browser.execute_script('arguments[0].scrollIntoView()', target)
- time.sleep(3)
- sfile = self.browser.get_screenshot_as_file('保存するパス' + self.Before_filename_2)
- print('get_screenshot2')
- print(sfile)
- time.sleep(3)
- menu = self.browser.find_element_by_class_name('クラス名')
- menu.click()
- time.sleep(2)
- signout = self.browser.find_element_by_id('signout')
- signout.click()
- time.sleep(2)
- self.browser.quit()
- print('close browser')
- def edit_img(self):
- args_imgMagick_1 = ['convert', self.Before_filename_1, '\( +clone -alpha opaque -fill white -colorize 100% \) +swap -geometry +0+0 -compose Over -composite -alpha off', self.After_filename_1]
- res = subprocess.run(args_imgMagick_1)
- args_imgMagick_2 = ['convert', self.Before_filename_2, '\( +clone -alpha opaque -fill white -colorize 100% \) +swap -geometry +0+0 -compose Over -composite -alpha off', self.After_filename_2]
- res = subprocess.run(args_imgMagick_2)
- def make_pdf(self):
- with open(self.pdfFileName_1, "wb") as f:
- f.write(img2pdf.convert(self.path_1))
- with open(self.pdfFileName_2, "wb") as f:
- f.write(img2pdf.convert(self.path_2))
- def move_files(self):
- move_jpg_1 = self.After_filename_1
- move_jpg_2 = self.After_filename_2
- move_pdf_1 = self.pdfFileName_1
- move_pdf_2 = self.pdfFileName_2
- now_MMDD = datetime.date.today()
- print(now_MMDD)
- check_dir = 'ディレクトリのパス' + str(now_MMDD)
- if os.path.isdir(check_dir) == True:
- print('the dir has found')
- pass
- else:
- os.mkdir(check_dir)
- print('made a dir')
- pickup_pdfs = glob.glob(os.path.dirname(os.path.abspath(__file__)) + '/PDF/z*.pdf')
- print(pickup_pdfs)
- if pickup_pdfs != None:
- for pickup_pdf in pickup_pdfs:
- shutil.move(str(pickup_pdf), check_dir + '/')
- else:
- pass
- shutil.move('ディレクトリのパス' + str(move_jpg_1), check_dir + '/' + str(move_jpg_1))
- shutil.move('ディレクトリのパス' + str(move_jpg_2), check_dir + '/' + str(move_jpg_2))
- shutil.move('ディレクトリのパス' + str(move_pdf_1), "PDFが保存してあるディレクトリのパス" + str(move_pdf_1))
- shutil.move('ディレクトリのパス' + str(move_pdf_2), "PDFが保存してあるディレクトリのパス" + str(move_pdf_2))
- def support_dashboard_loop():
- SUPPORT_DASHBOARD = support_dashboard()
- SUPPORT_DASHBOARD.get_screenshot()
- SUPPORT_DASHBOARD.edit_img()
- SUPPORT_DASHBOARD.make_pdf()
- SUPPORT_DASHBOARD.move_files()
- if __name__ == "__main__":
- support_dashboard_loop()
苦労したこと
ブラウザ処理、、全体的に難しかったです⊂⌒~⊃。Д。)⊃
特に
- 要素の取得
- ブラウザ終了処理
に時間がかかりました。
要素の取得では、ページの移動やスクロールする際にページの要素がうまく取得できないことが多くありました。
これはtime.sleepで数秒待機させることでうまくいきました。
ページが完全に移動する前に実行されてたみたいでした(´・ω・`)
ブラウザ終了処理では、最初にスクリーンショットを取得した後、ブラウザを閉じる処理を入れていなかったので
cronで定期的に実行するたびにchromeのプロセスがだるま式で増えていき、ラズパイが固まる…ってことが多々ありました…(;^ω^)
ブラウザの終了処理を追加しても「if __name__ == "__main__":」を入れておらず
メインスクリプトの多重起動チェックを行う前(importの時点)で処理が実行されてしまい、プロセスがだるま式に…ということもありました((((;゚Д゚))))
「if __name__ == "__main__":」、コレダイジ
さいごに
今回の開発を通して、ヘッドレスブラウザ処理の書き方やページの仕組みを学びました。
今後はバグの修正などに取り組んでいきます。
最後までお読みいただきありがとうございました。





![[日本語化]クラウド SIEM ダッシュボードと KPI を毎日のスタンドアップで使用して SOC の効率を向上させる方法](http://www.sumologic.com/wp-content/uploads/CloudSIEMdashboards_Blog_header_700x200-1-1.png)
