みなさま、こんにちは
Tachanです。
今回はOCIのデータ・サイエンスサービスを使い、アヤメの品種判別を機械学習させる記事を書いていこうと思います。
Part1はデータ・サイエンスサービスの概要とセットアップについてご紹介していきます。
サービス概要
データ・サイエンスとは、OCI上で提供されている機械学習プラットフォームサービスです。
データの可視化から機械学習モデルの作成、学習、評価まで行うことができます。
データ・サイエンスの特徴は主に3つあります。
1.機械学習のライフサイクルをサービス内で完結
このサービスでは、Oracle Accelerated Data Science (ADS) SDKが実装されたコンピュートを使用することができます。
Oracle Accelerated Data Science (ADS) SDKとは、Oracle独自のpythonライブラリであり、
機械学習モデルのライフサイクルに関わるすべてのステップをカバーするインターフェースを提供しています。
2.他のユーザーに共有が可能
作成した開発環境や、データ、学習済み予測モデルを複数のユーザーに共有することができます。
これにより、ノウハウやリソースの共有、また共同開発が可能となります。
3.安価な課金体系
データ・サイエンスの利用料は、使用したコンピュート、ストレージ、ネットワークといった IaaSリソースのみ課金されます。PaaSのリソースは無償です。
リソースの事前準備
データサイエンスを利用するには、次の事前準備が必要です。
- VCN、サブネットの作成
- 動的グループの作成
- ポリシーの作成
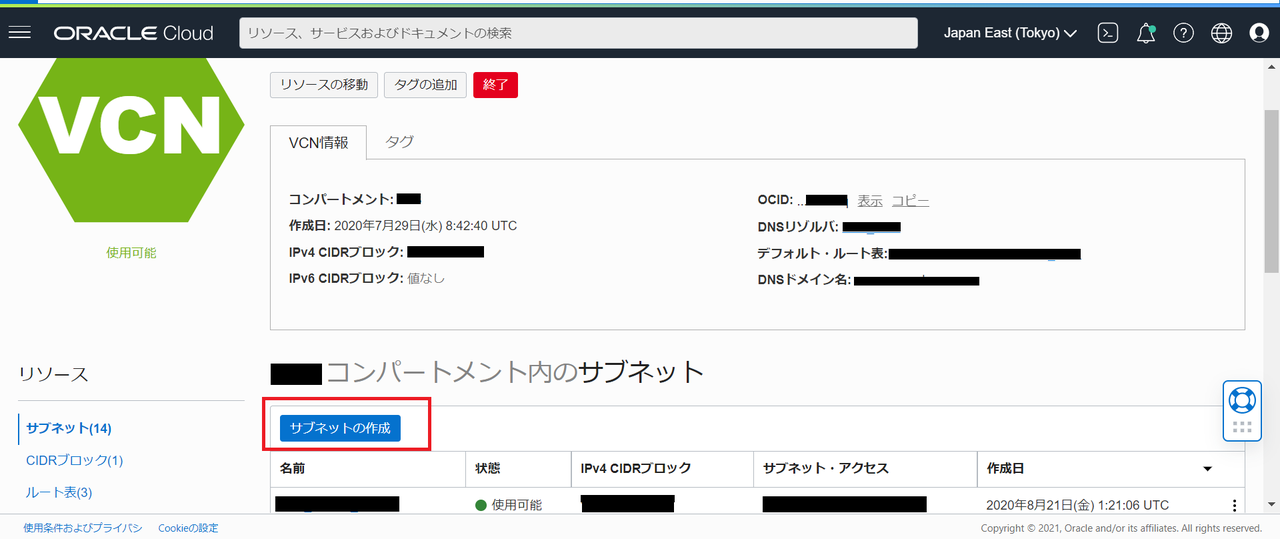
1.VCN、サブネットの作成
データ・サイエンスを利用するにあたってノートブック・セッションを作成するのですが、
これはサブネット内に配置されるので、VCN、サブネットの作成が必要です。
VCN、サブネットは ホーム > ネットワーキング > 仮想クラウド・ネットワーク から作成できます。
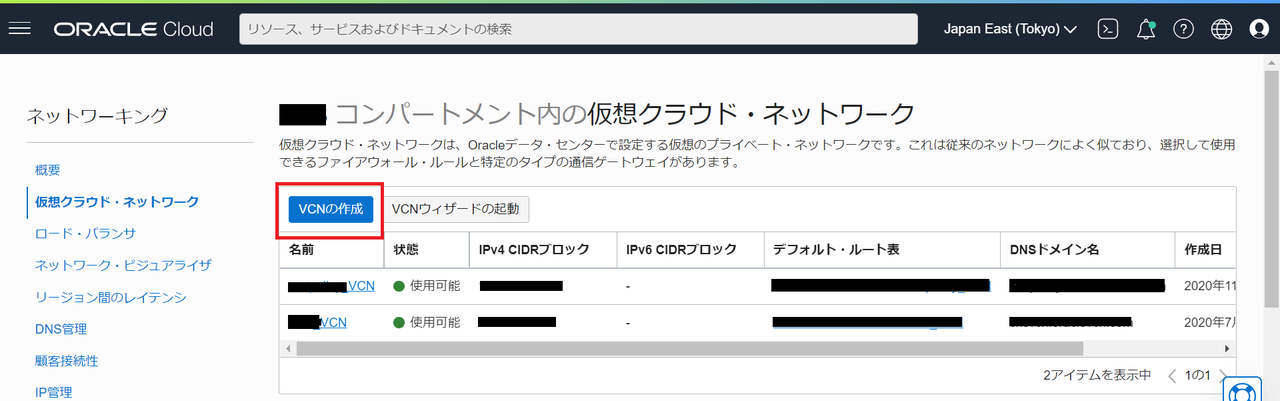
また、ネットワークを一から作成する場合、ウィザードでVCNに関連するリソースを一度に作成する方法もあります。
ウィザードでの作成方法はこちら
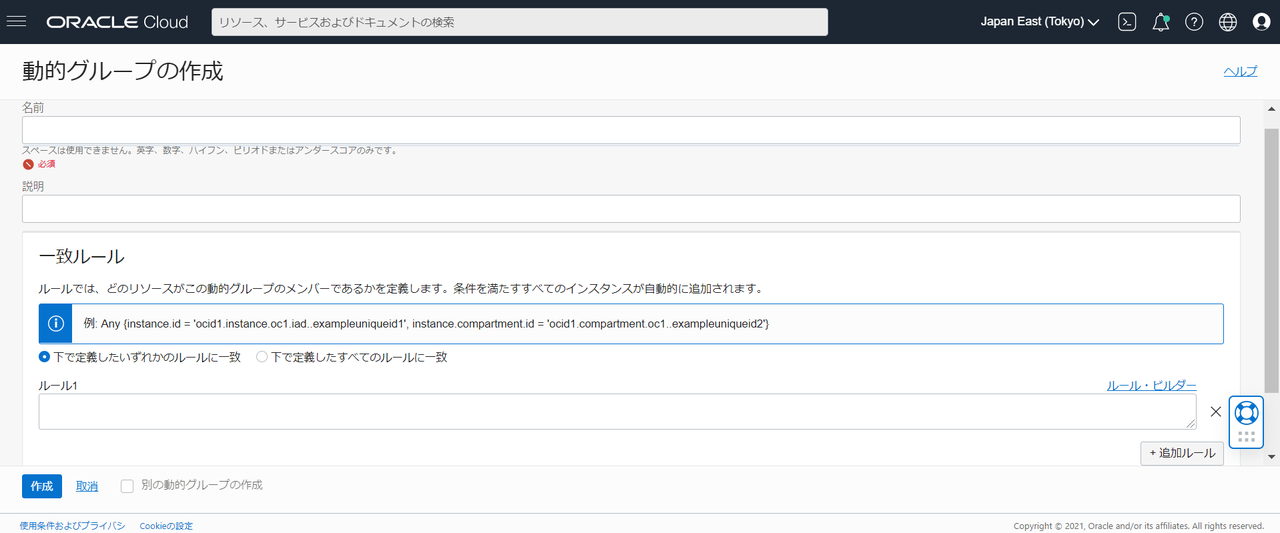
2.動的グループの作成
ノートブック・セッションを使用中に他のOCIリソースにアクセスする場合に必要になります。
動的グループは ホーム > アイデンティティとセキュリティ > 動的グループ から作成できます。
一致ルールには、使用するリソースにアクセス権を付与する内容を書き、ルールに合致するリソースは動的グループに追加されます。
ルールの記述例については以下のドキュメントから確認できます。
https://docs.oracle.com/ja-jp/iaas/data-science/using/create-dynamic-groups.htm#creating_dynamic_groups_and_policies
3.ポリシーの作成
データ・サイエンス関連リソースおよびネットワーク・リソースへのアクセス権を付与するために、
ポリシーを設定する必要があります。
3-1. データ・サイエンス・リソースへのアクセス権の付与
データ・サイエンスを使用するユーザーが、プロジェクト、ノートブック・セッションおよびモデルを作成する場合、
以下のポリシーを設定します。
allow group グループ名 to manage data-science-family in compartment コンパートメント名
3-2. データ・サイエンス・グループにネットワーク・リソースへのアクセス権を付与
ユーザーが、ノートブック・セッションを作成する場合、VCNおよびサブネットへのアクセスが必要です。
以下のポリシーを設定します。
allow group グループ名 to use virtual-network-family in compartment コンパートメント名
3-3. データ・サイエンスのサービスアクセスをネットワーク・リソースに付与
ノートブック・セッションを作成する際、データ・サイエンスのサービスは作成するサブネットにアクセスできる必要があるため、以下のポリシーを設定します。
allow service datascience to use virtual-network-family in compartment acme-network
以上で事前準備が終わりました。
次はデータ・サイエンスのセットアップを行います。
データ・サイエンスのセットアップ
以下では、実行環境を構築していきます。
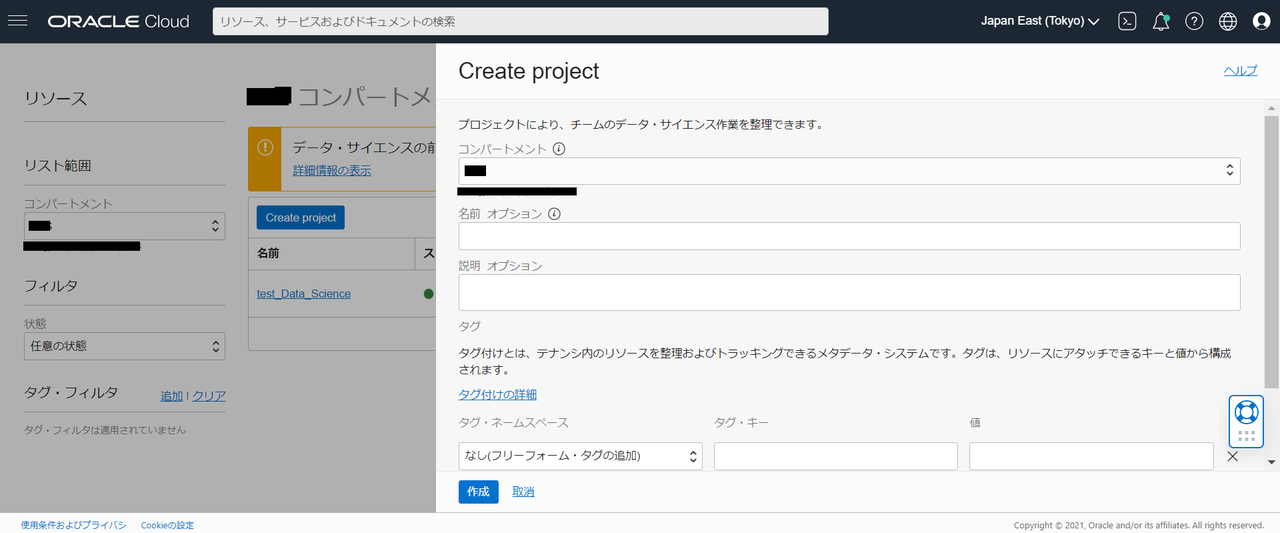
まずは、プロジェクトを作成します。プロジェクトは作業するコンテナのようなイメージです。
メニュー > アナリティクスとAI > データ・サイエンス を選択し、
作成ボタンからプロジェクトの作成を行います。※作成するコンパートメントに注意
次にノートブック・セッションを作成します。
ノートブック・セッションは機械学習モデルを構築、トレーニングする対話型コーディング環境を指します。
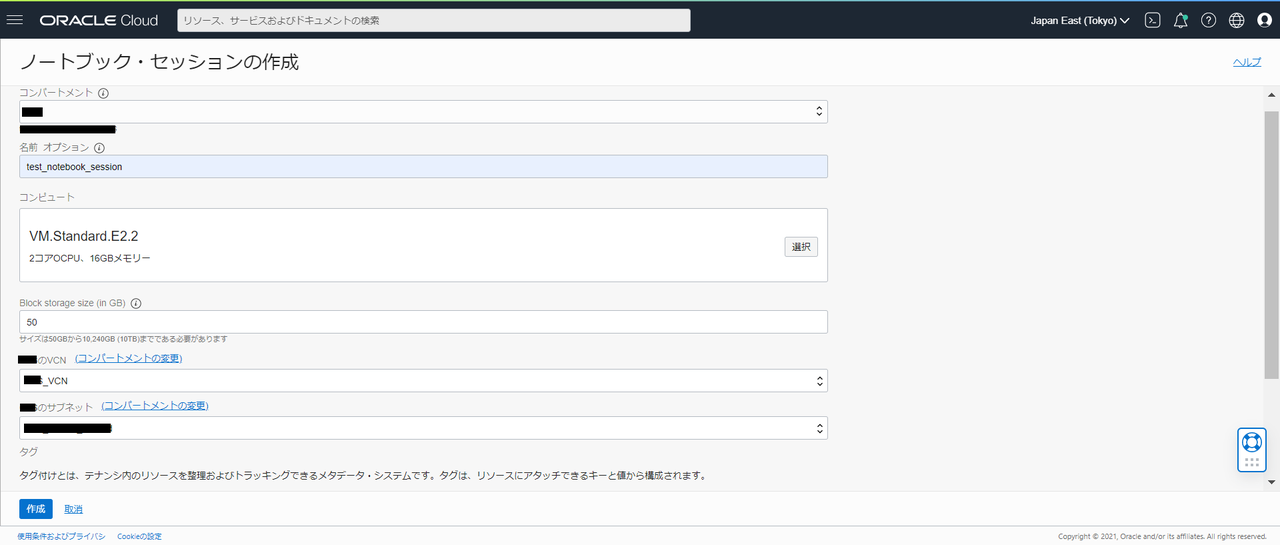
ノートブック・セッションの作成に失敗する場合、ポリシーが正しく許可されているか見直しましょう。
ノートブック・セッション作成後、開くを押すとJupyterLab(対話型開発環境(IDE))に接続ができました。
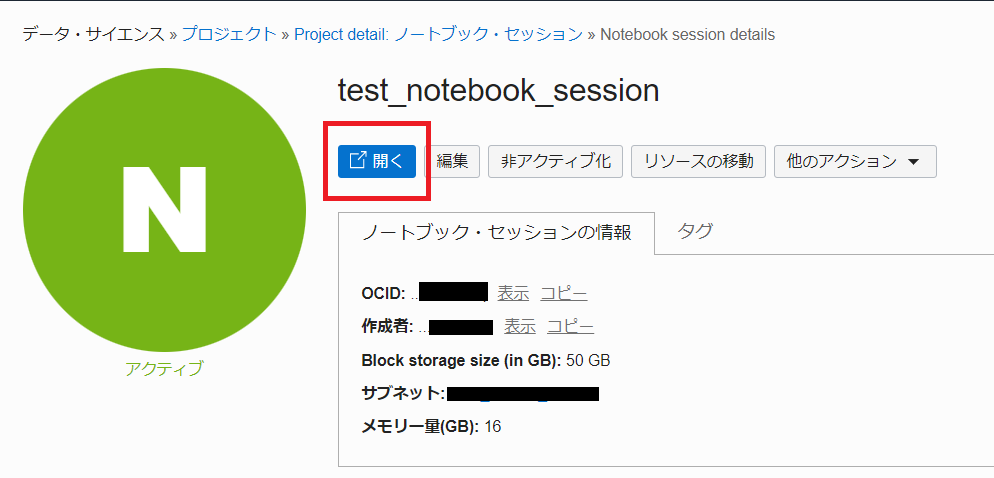
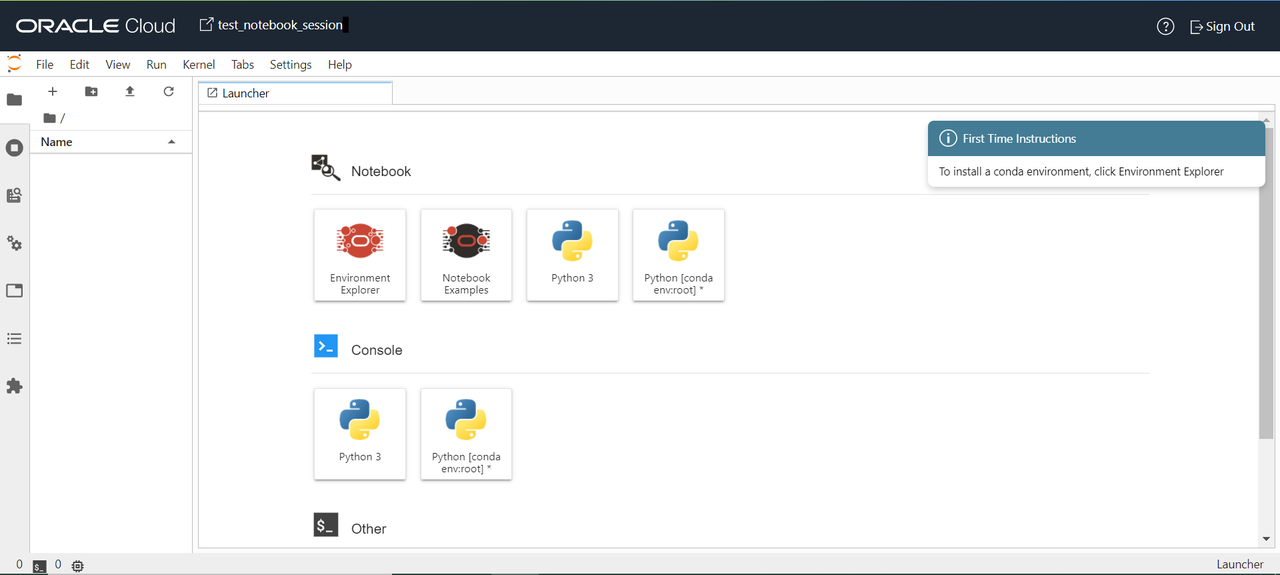
次回は、データ・サイエンスでサンプルデータを分類し、品種判別を行っていきます。
最後までお読みいただきありがとうございました。
Part2へ続きます!





![[日本語化]クラウド SIEM ダッシュボードと KPI を毎日のスタンドアップで使用して SOC の効率を向上させる方法](http://www.sumologic.com/wp-content/uploads/CloudSIEMdashboards_Blog_header_700x200-1-1.png)
